
Rendered evidence
Store JavaScript-rendered HTML alongside status codes, canonicals, and redirect chains for each URL.
How we help
Run a local crawl that keeps the rendered DOM close to the live page, then explore URLs, headings, and link graphs inside one workspace built for technical SEO.
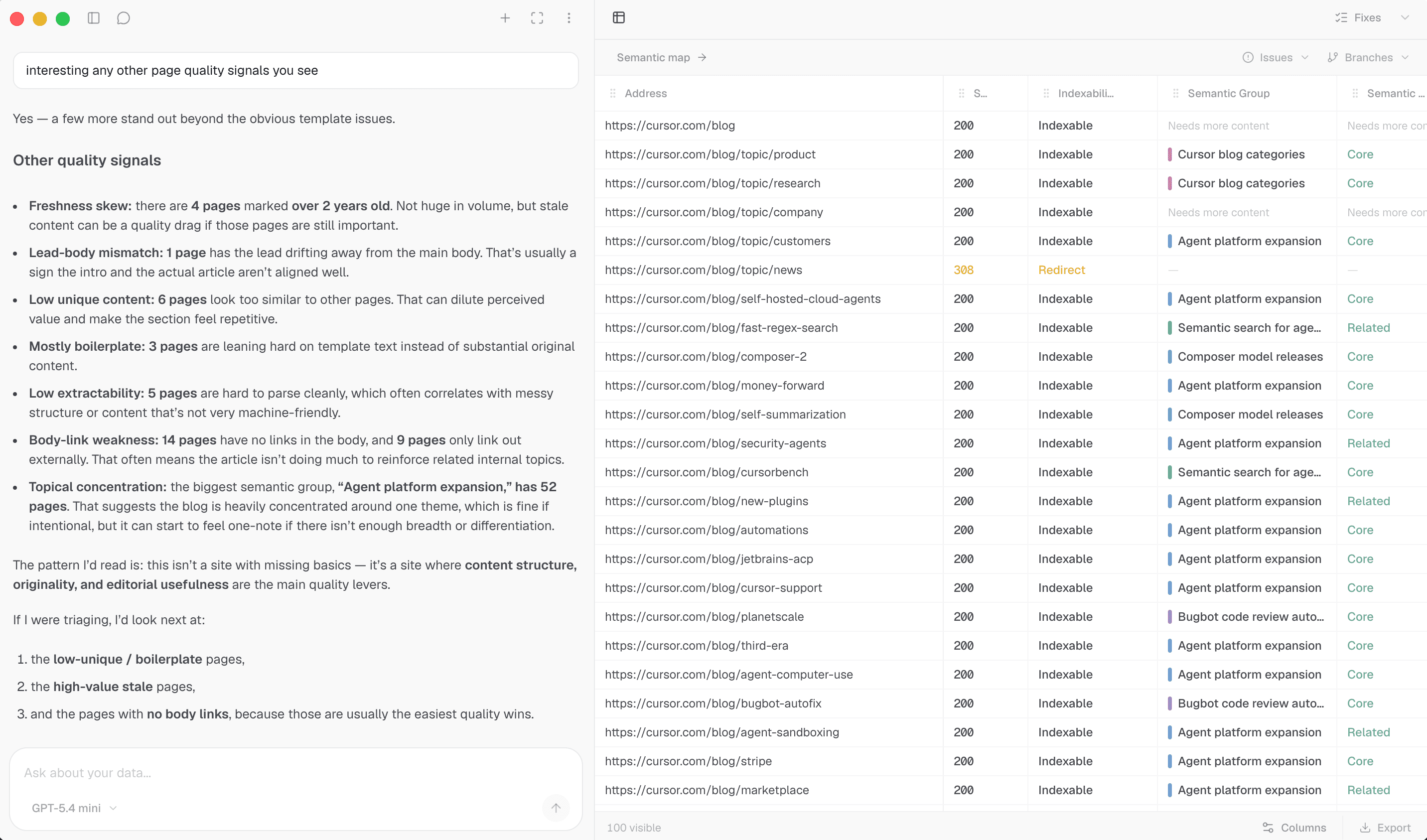
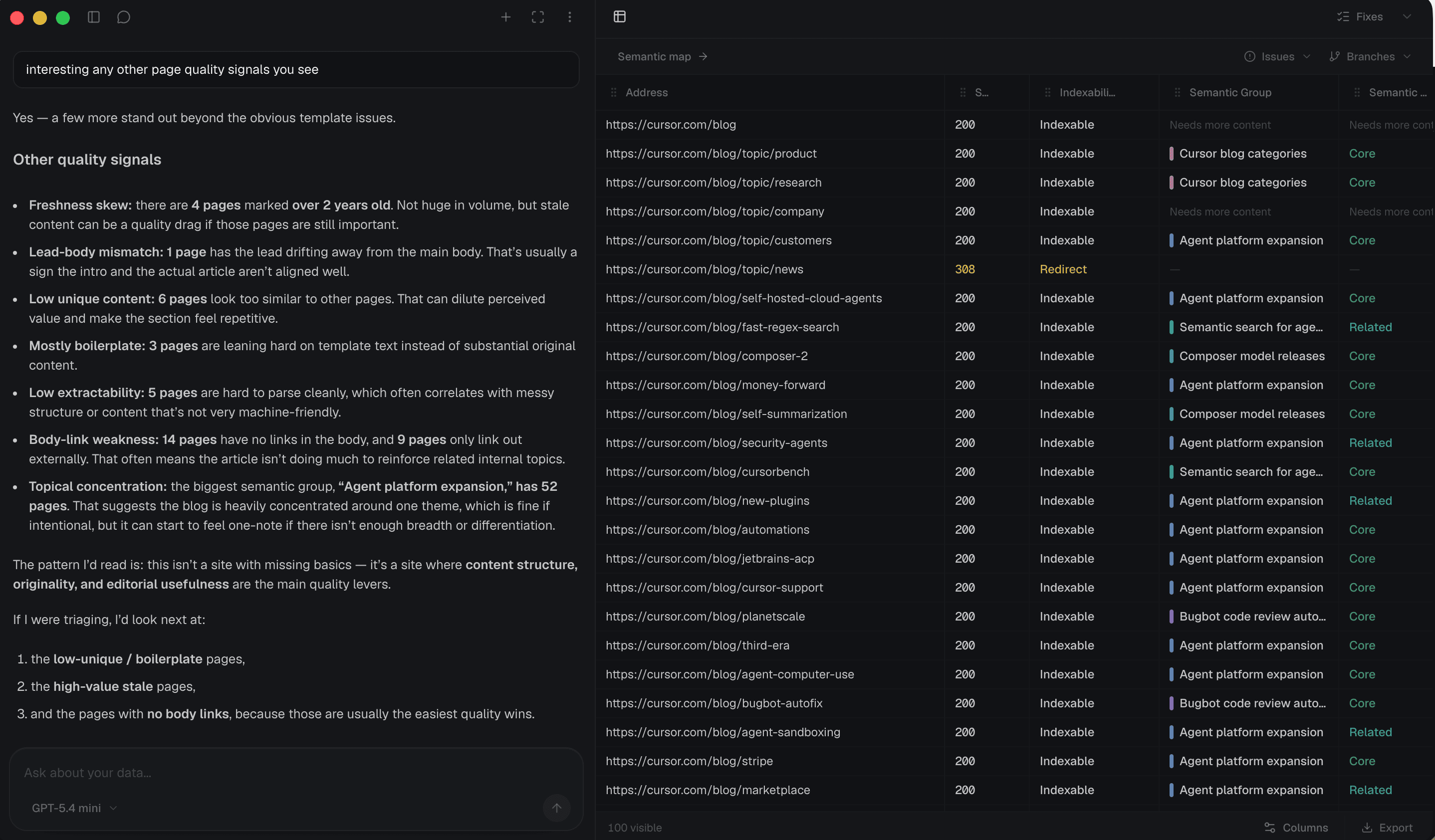
Store JavaScript-rendered HTML alongside status codes, canonicals, and redirect chains for each URL.
See inlinks, outlinks, and depth without exporting to another visualization tool.
Group URLs by directory and page type so repeated issues surface faster than row-by-row review.
Let agents query the crawl directly instead of pasting CSV snippets into a chat window.
Move from crawl to prioritized technical findings in one focused workspace—without rebuilding the story in docs and slides.
Search and compare pages by meaning, entities, and topical overlap—not just exact keyword matches in a spreadsheet.
Connect technical findings to fix lists and execution so optimization work does not stall in another spreadsheet.
Download
Download Pagebrain and build a queryable workspace from your next technical SEO crawl.
Contact team