Rendered page content
Capture client-rendered copy, navigation, modules, and dynamic content that static HTML crawls can miss.
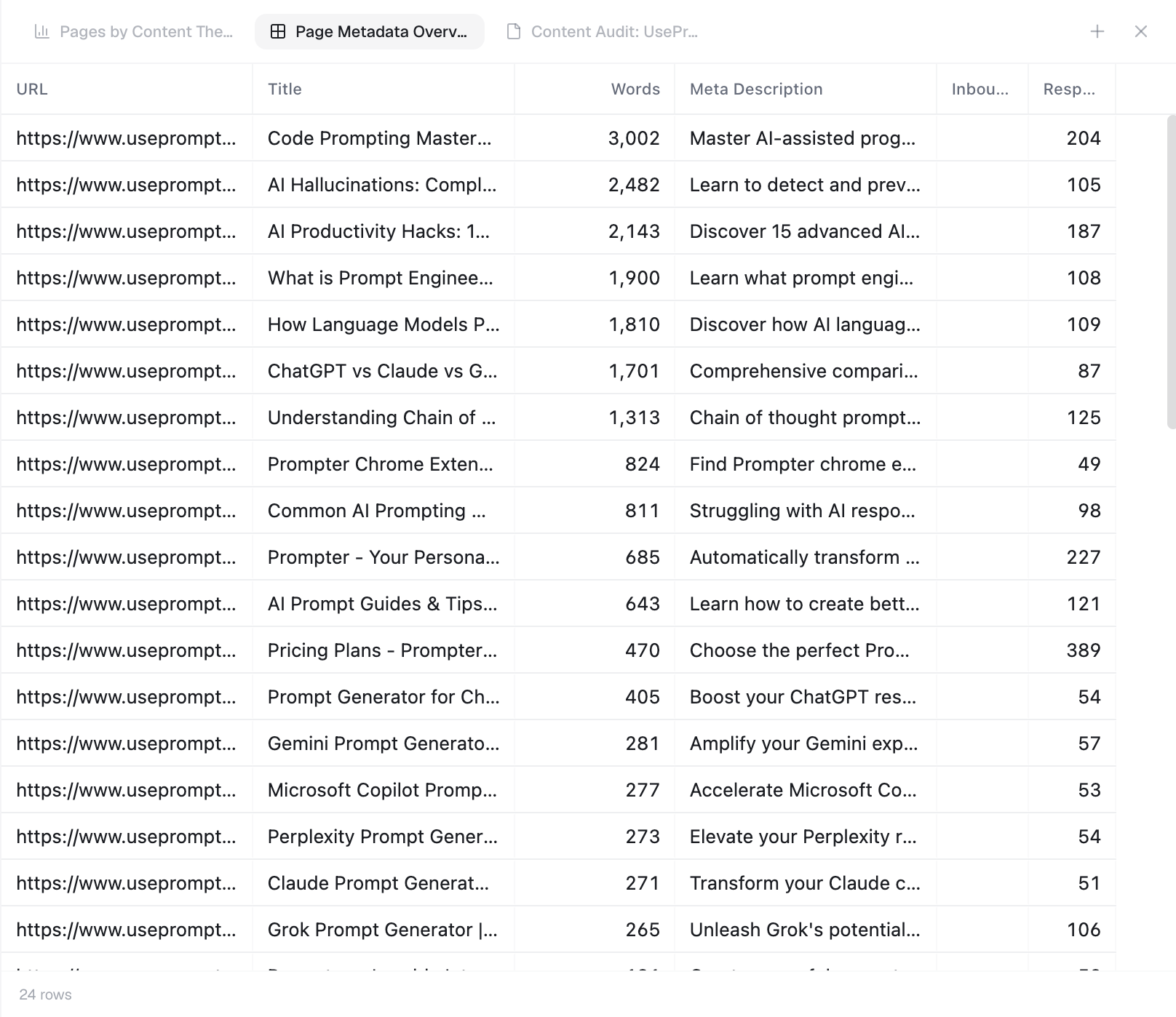
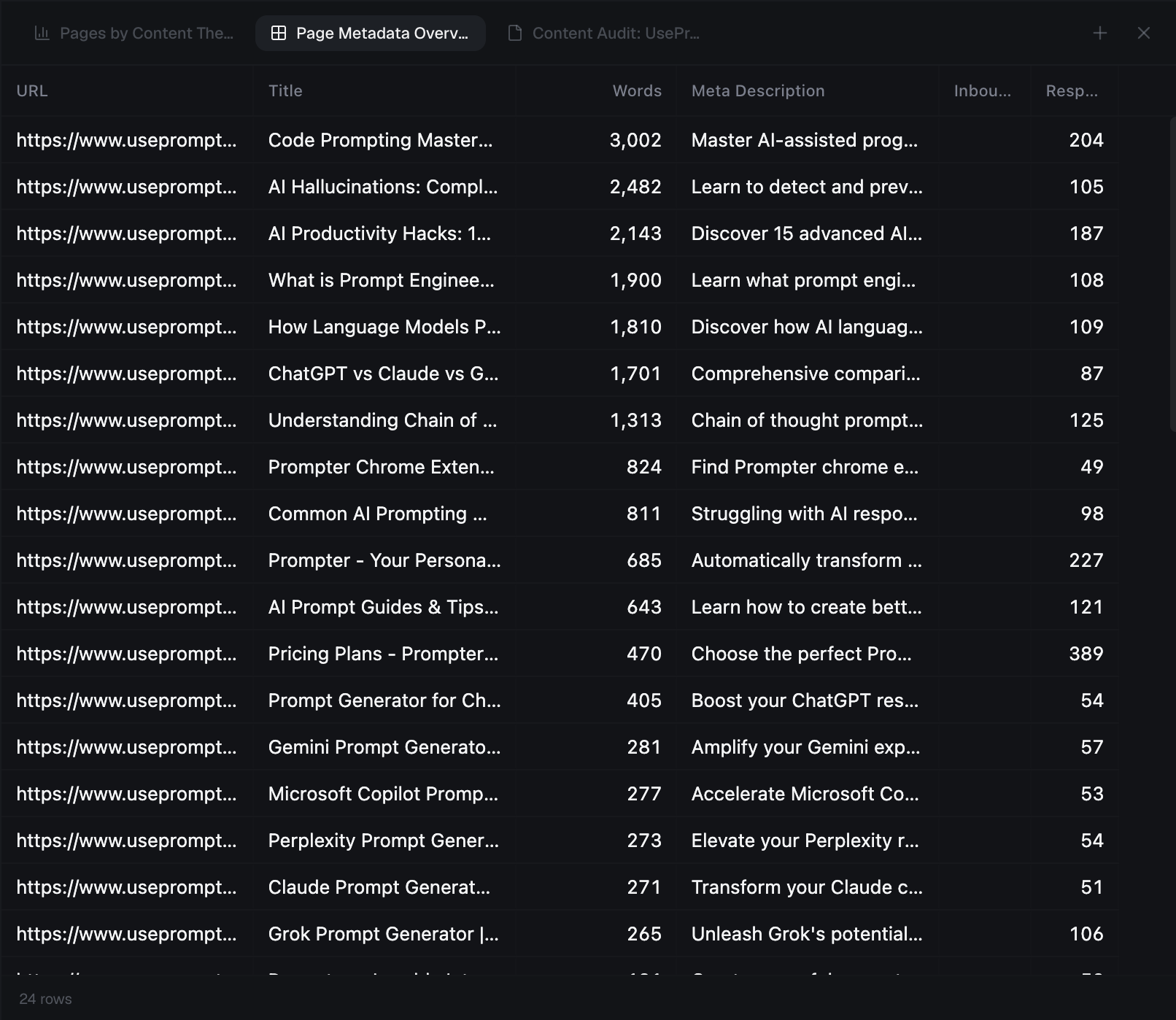
PageBrain renders JavaScript, extracts HTML, metadata, links, headings, and structure, then converts important content into clean markdown for analysis.
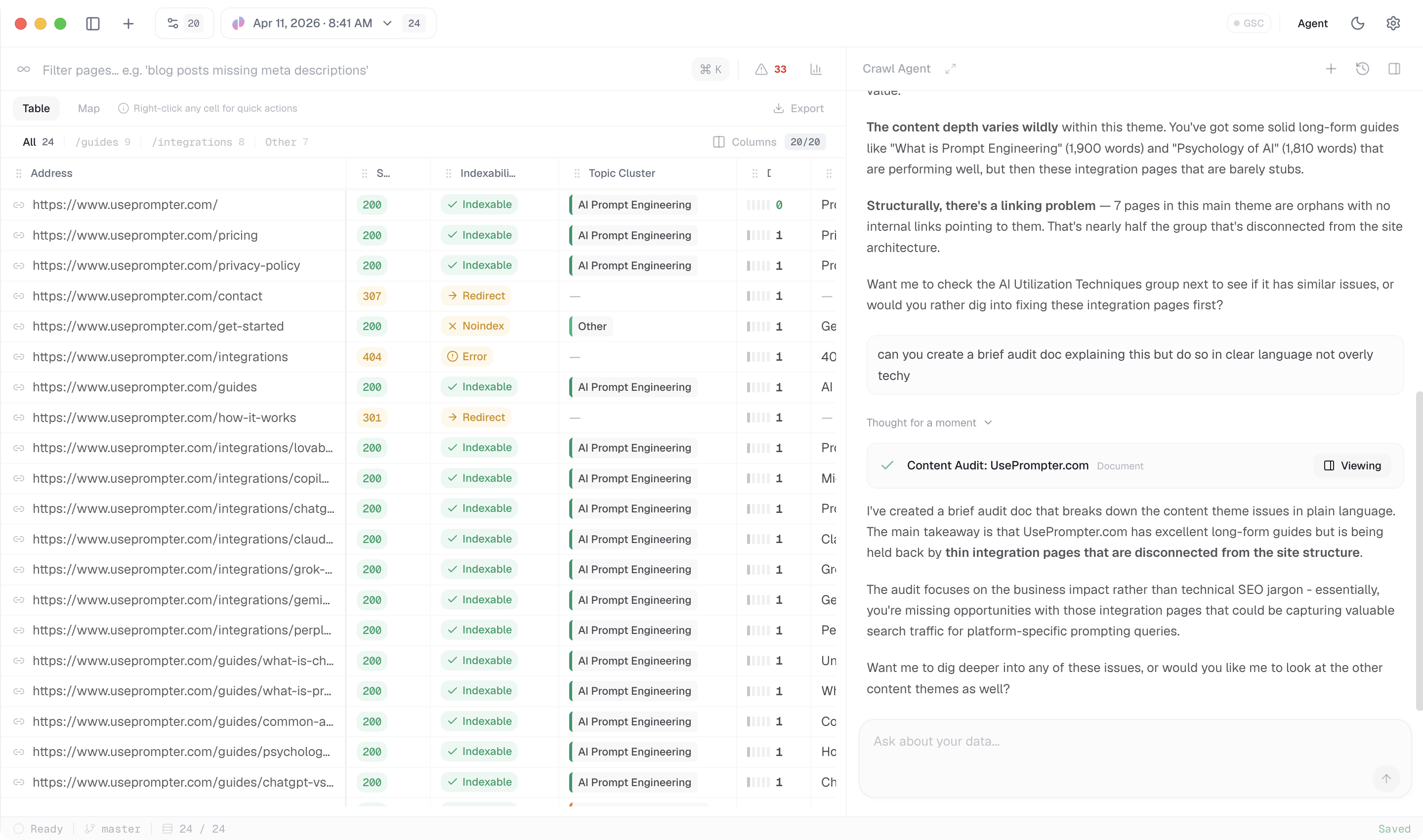
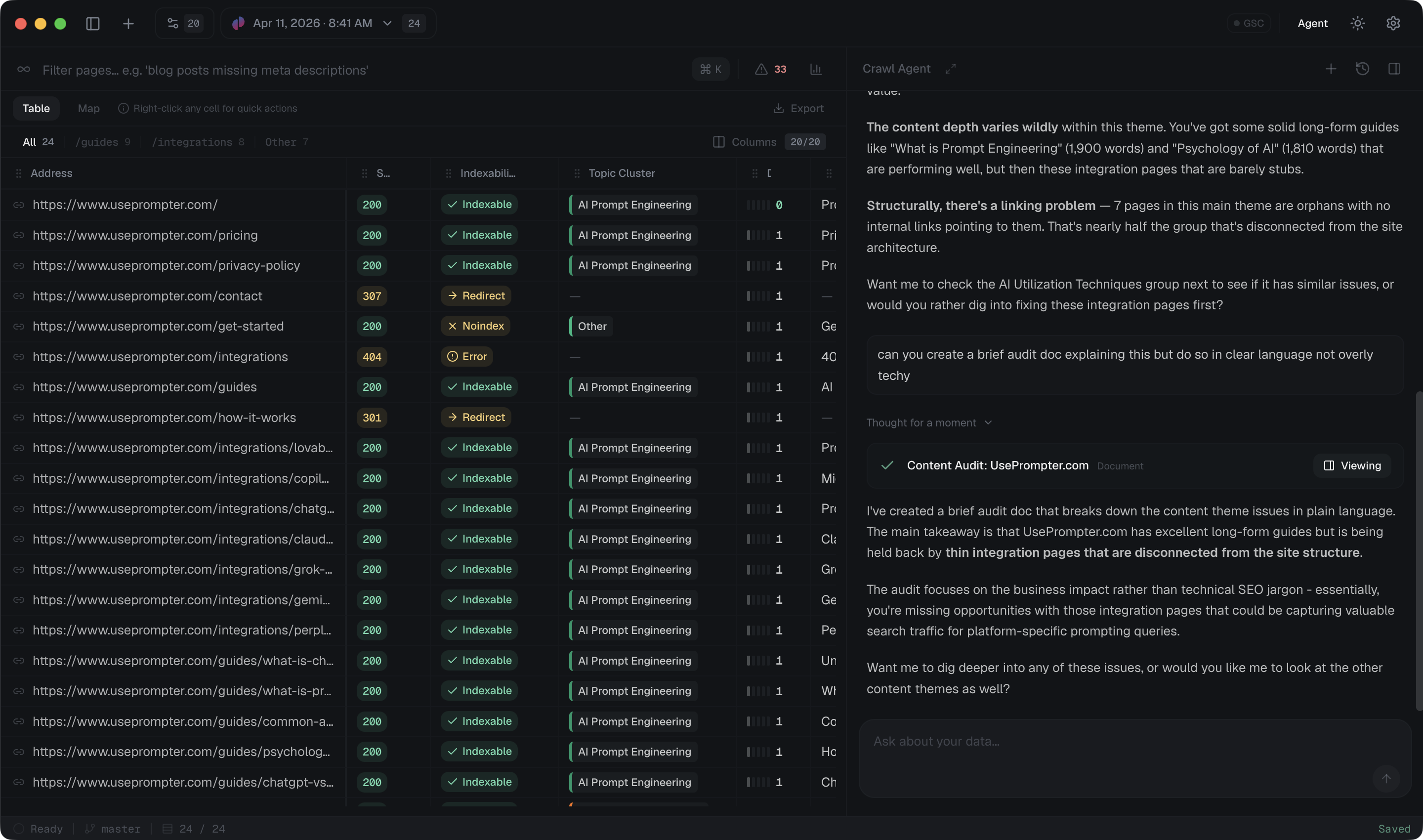
Enter a site, choose the pages that matter, and let PageBrain render and collect the live content.
Capture technical SEO fields, rendered text, headings, links, page structure, and source content for each URL.
Chunk, embed, and structure every page so related capabilities can compare, extract, and reason across the site.
Capture client-rendered copy, navigation, modules, and dynamic content that static HTML crawls can miss.
Extract titles, descriptions, canonicals, headings, status codes, indexability, and other technical signals.
Understand how pages connect, which templates create links, and where important content may be isolated.
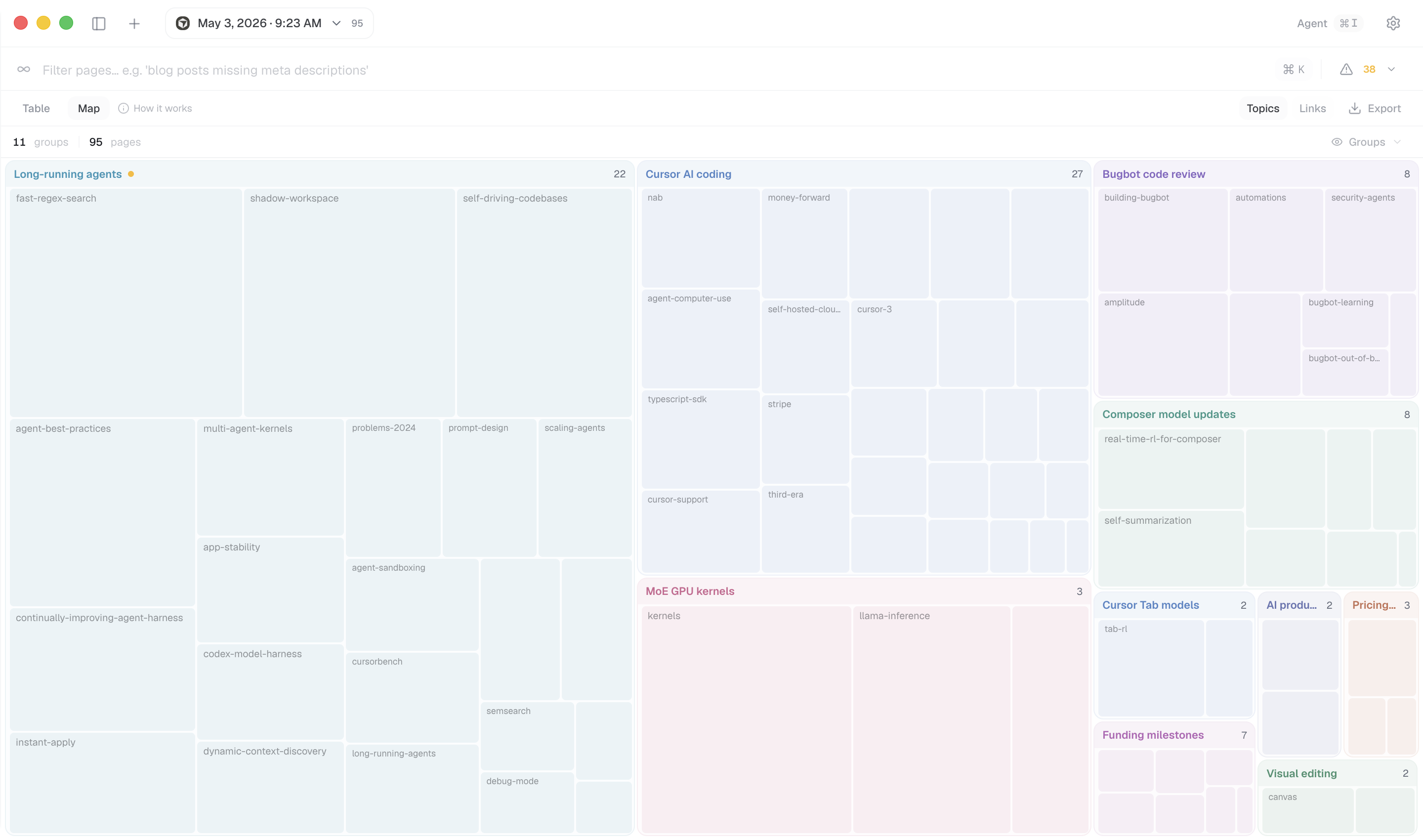
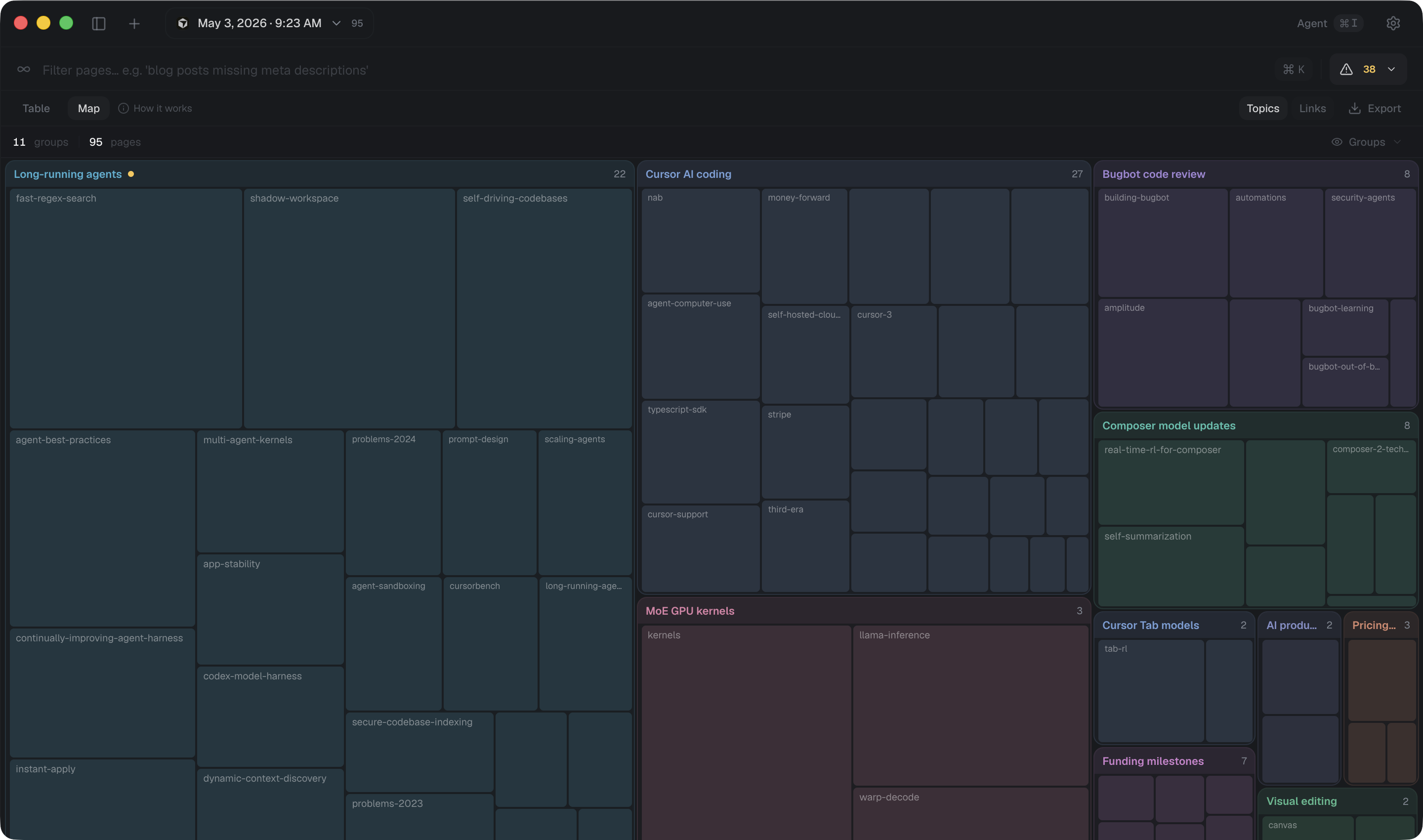
Convert meaningful page content into a cleaner format for semantic extraction, agents, and audit workflows.
Package technical fields, rendered content, links, and source context so downstream analysis keeps its grounding.
Focus the crawl on the site sections that matter and avoid wasting attention on noisy or low-value URL patterns.
Ready to try technical scraping? Download PageBrain and start building website intelligence from your next crawl.
Download free